Tag: Marzyeh Ghassemi


A better method for identifying overconfident large language models
Large language models (LLMs) can generate credible but inaccurate responses, so researchers have developed uncertainty quantification methods to check the reliability of predictions. One popular method involves submitting the same prompt multiple times to see if the model generates the same answer.But this method measures self-confidence, and even the most impressive LLM might be confidently wrong. Overconfidence can mislead users about the accuracy of a prediction, which might result in devastating consequences in high-stakes settings like health care or finance.
To address this shortcoming, MIT researchers introduced a new method for measuring a different type of uncertainty that more reliably identifies confident but incorrect LLM responses. Learn more


AI medical tools downplay symptoms in women and ethnic minorities
Research by the MIT’s Jameel Clinic in June found that AI models, such as OpenAI’s GPT-4, Meta’s Llama 3 and Palmyra-Med — a healthcare- focused LLM — recommended a much lower level of care for female patients, and suggested some patients self-treat at home instead of seeking help.A separate study by the MIT team showed that OpenAI’s GPT-4 and other models also displayed answers that had less compassion towards Black and Asian people seeking support for mental health problems.
That suggested “some patients could receive much less supportive guidance based purely on their perceived race by the model”, said Marzyeh Ghassemi, associate professor at MIT’s Jameel Clinic. Learn more

Can artificial intelligence cause medical errors? This MIT researcher shows it can.
Could a misspelled word cause a medical crisis? Maybe, if your medical records are being analyzed by an artificial intelligence system. One little typo, or even the use of an unusual word, can cause a medical AI to conclude there’s nothing wrong with somebody who might actually be quite sick. It’s a real danger, now that hospitals worldwide are deploying systems that use AI software like ChatGPT to assist in diagnosing illnesses. The potential benefits are huge; AIs can be excellent at spotting potential health problems that a human physician might miss. But new research from Marzyeh Ghassemi, a professor at the Massachusetts Institute of Technology and principal investigator at MIT Jameel Clinic, also finds that these AI tools are often remarkably easy to mislead, in ways that could do serious harm. Learn more

MIT and Mass General Hospital researchers find disparities in organ acceptance
Most computational research in organ allocation is focused on the initial stages, when waitlisted patients are being prioritized for organ transplants. In a new paper presented at ACM Conference on Fairness, Accountability, and Transparency (FAccT) in Athens, Greece, researchers from MIT and Massachusetts General Hospital focused on the final, less-studied stage: organ offer acceptance, when an offer is made and the physician at the transplant center decides on behalf of the patient whether to accept or reject the offered organ. Learn more
AI doesn’t know ‘no’ – and that’s a huge problem for medical bots
Toddlers may swiftly master the meaning of the word “no”, but many artificial intelligence models struggle to do so. They show a high fail rate when it comes to understanding commands that contain negation words such as “no” and “not”.That could mean medical AI models failing to realise that there is a big difference between an X-ray image labelled as showing “signs of pneumonia” and one labelled as showing “no signs of pneumonia” – with potentially catastrophic consequences if physicians rely on AI assistance to classify images when making diagnoses or prioritising treatment for certain patients.
It might seem surprising that today’s sophisticated AI models would struggle with something so fundamental. But, says Kumail Alhamoud at the Massachusetts Institute of Technology, “they’re all bad [at it] in some sense”. Learn more
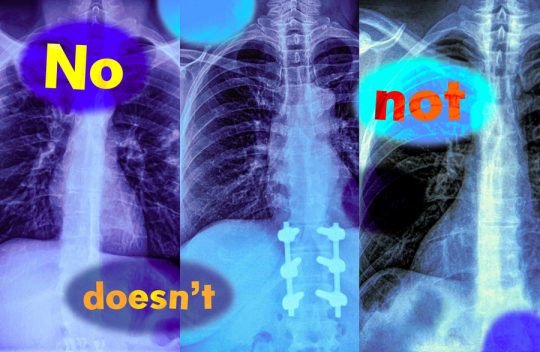
Study shows vision-language models can’t handle queries with negation words
Imagine a radiologist examining a chest X-ray from a new patient. She notices the patient has swelling in the tissue but does not have an enlarged heart. Looking to speed up diagnosis, she might use a vision-language machine-learning model to search for reports from similar patients.But if the model mistakenly identifies reports with both conditions, the most likely diagnosis could be quite different: If a patient has tissue swelling and an enlarged heart, the condition is very likely to be cardiac related, but with no enlarged heart there could be several underlying causes.
In a new study, MIT researchers have found that vision-language models are extremely likely to make such a mistake in real-world situations because they don’t understand negation — words like “no” and “doesn’t” that specify what is false or absent. Learn more