Health AI Has a Standards Problem. Researchers Want to Fix It.
If progress is a stairwell to be climbed, then foundational knowledge is the floor from which it arises. Without establishing basic standards, the task of achieving, measuring, reproducing, and legitimizing scientific progress becomes nearly impossible. In medicine, standards not only represent a benchmark for advancement, but also an essential prerequisite for safety.
A team of researchers across 14 institutions, including MIT, are now advocating for new data standards when it comes to applying artificial intelligence to electronic health records (EHRs), i.e., health AI. Their paper, recently published in the New England Journal of Medicine AI (NEJM AI), proposes a framework titled Medical Event Data Standard (MEDS), which aims to standardize the way health data is formatted, described, and exchanged.
This principle is central to MEDS: rather than taking a one-size-fits-all approach to making trained models operable across different hospital systems, MEDS is focused on scaling the training process for models via a standardized data schema. This standard assumes that each hospital will train its own model locally on its own data, but with a process that makes the training reproducible and consistent. This localized approach has the added benefit of allowing data to stay within the hospital, reducing potential risks to patient privacy.
“MEDS is a simple way to make all different sources of electronic health record (EHR) data ‘look the same’ to your code, regardless of what hospital or clinic or EHR software system the data came from.” says first author Matthew McDermott, an Assistant Professor at Columbia University who graduated from the lab of Jameel Clinic Principal Investigator Pete Szolovits last year. “This is helpful because it lets researchers everywhere share their code and their algorithms with one another, then test those algorithms on their own local datasets.”
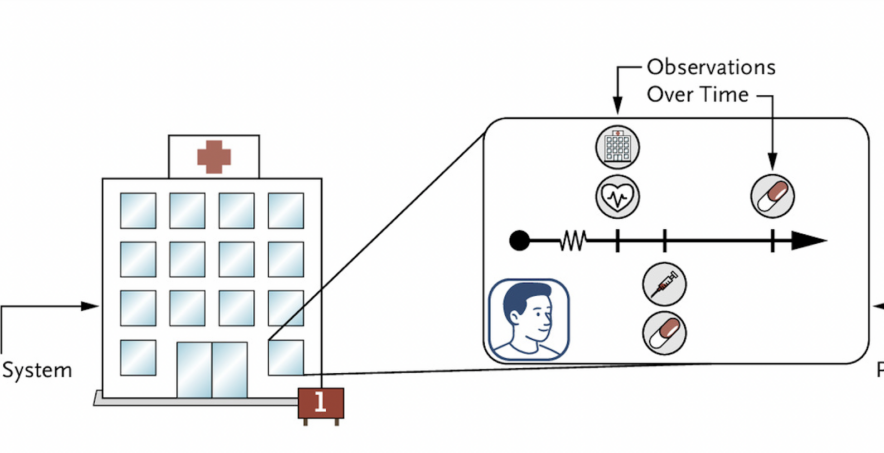
To understand the gap that MEDS wants to bridge, it’s helpful to compare the standardized data practices in health informatics to current data approaches in health AI. In health informatics, observational studies are conducted with curated patient populations to produce data that generalizes well to statistical models (e.g., regression analysis) across health systems.
But the standards applied to health informatics were intended to format datasets for statistical models, which are very different to today’s foundation AI models. For instance, statistical models typically have fewer than a hundred parameters, whereas the parameters for foundation models are often on the order of hundreds of millions to hundreds of billions.
Moreover, many clinical foundation models are trained and evaluated on all-inclusive, historical EHR data based on care patterns within a single data source, rather than curated cohorts. Instead of specific features, these models are fed every diagnosis, every lab result, and every medication that a patient has ever had with the aim of improving prediction capabilities.
“The value of MEDS is not only technical but infrastructural,” says Tom Pollard, co-author and a Research Scientist at MIT. “It gives hospitals and researchers a more practical way to evaluate AI methods on their own patient populations, without requiring every institution to rebuild the same data pipeline from scratch.”
For example, a foundation model trained on data from Massachusetts General Hospital may not perform as well on patients in a rural clinic in Texas, and the training data must undergo a data harmonization process prior to retraining. The Observational Medical Outcomes Partnership Common Data Model (OMOP-CDM) is a commonly used open community data standard for statistical models with 400 fields across 40 distinct tables, meaning a foundation model’s all-inclusive EHR dataset must be harmonized with OMOP’s 400 fields and 40 tables before retraining can start.
In contrast, the MEDS data schema only requires three fields, with several optional fields to train or retrain foundation models. For datasets that have already been harmonized with health informatics data standards like OMOP or Fast Healthcare Interoperability Resources (FHIR), MEDS also acts as a complementary tool converting those formats into the MEDS format.
“Our hope is that MEDS will allow the health AI research community to do better, more reliable research, faster, ultimately leading to much better models that can predict what will happen to patients given their EHR data,” says McDermott. “We’re already seeing some of this now, with MEDS having played a major role in the emergence and ease of use of the new, autoregressive, foundation models over raw EHR data like ETHOS or Curiosity.”
McDermott acknowledges that for patients, these innovations will take a long time to translate into improvements in care. “But we hope that with better AI capabilities on medical data, this will ultimately lead to better care for patients,” he says. “Especially for complex, longitudinal diseases where AI has a lot of potential to significantly improve patient outcomes and experience.”